

Background
New York City's vibrant taxi ecosystem faces a unique challenge. While Yellow Taxis operate under strict city-issued medallions—13,587 in circulation—they lack a centralized dispatch system. As a result, drivers rely heavily on intuition and experience to find passengers. Yet demand patterns evolve constantly, influenced by time of day, holidays, local events, and shifting rider habits. These changes are hard to detect in real time, leaving room for inefficiency and missed opportunities.


This project introduces a cloud-native, automated pipeline that empowers drivers with hourly predictions of high-demand pickup zones. The system leverages historical trip data, engineering modularity, and scalable infrastructure to support timely decisions—segmented by weekdays vs holidays and busy vs non-busy hours.
A modular Data Engineering and Machine Learning pipeline to:
Ingest, clean, and transform +100M records NYC Yellow Taxi trip data
Implement star schema modeling for efficient analytics
Train predictive ML models on time-based spatial features
Automated deployment with Docker and Docker Hub
CI/CD workflows via GitHub Actions
Compute and Persist data using cloud-native platform (GCP/ AWS)
Build application with Streamlit
Solution
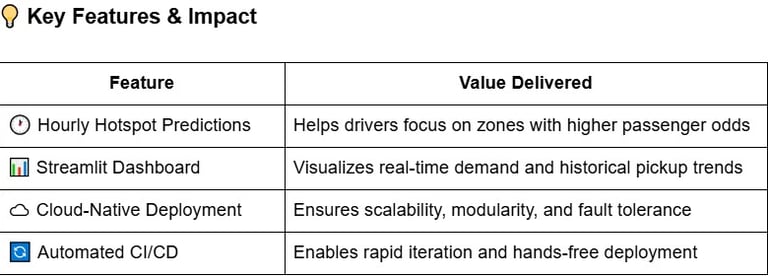
This project embodies how data engineering, ML modeling, and cloud-native infrastructure can converge into a scalable solution for urban mobility. By empowering NYC taxi drivers with predictive insights, the system transforms intuition into informed strategy. The modular design allows future extension into weather-adjusted forecasting, surge pricing analysis, and integration with city planning tools—highlighting the practical power of machine learning in dynamic, real-world scenarios.



Mario Rustiadi

★★★★★
Just Me and My Data
Hey, I'm Mario 👋 I’m a stats guy from the social sciences who kind of stumbled into the world of big data. I love working with data... For me, turning raw data into solution is one connected journey.
I can help you make better data decisions for your business. Or maybe you're just thinking of jumping into big data too—welcome aboard! I'm always open for collaborations that bring mutual value and good energy.
FYI: I’m no frontend or fullstack wizard—so this site’s look is pretty bare-bones. Hope it’s usable! Happy to get feedback or just chat. Thanks for stopping by...